Introduction to Pikala
Over the last few months I’ve collected a few problems from work and open source projects that last week I realised could all be solved by the same tool.
But that tool, as far as I could find, didn’t really exist. So I spent the weekend writing it, and this is the post to introduce it.
Problems
Spark dotnet with jupyter lab
Spark dotnet is a dotnet library wrapping Apache Spark. It can be used to write spark applications in C#/F# and then submit those to be run on a spark cluster.
It also (like java spark) allows you to create User Defined Functions (UDF) which can run arbitrary code on the cluster. In a normal application this is done by adding your application binary to the files distributed as part of the spark jobs and then serializing a small structure with the type and method names that should be reflectively loaded for the UDF.
This is reasonable for built applications but it doesn’t work with jupyter notebooks. Currently spark dotnet has a notebook extension for C# notebooks that grabs the Rosyln compilation unit that the notebook is building and distributes that .dll as part of the spark job. However this has a few issues. Firstly it has some corner cases due to how objects are serialized. Secondly this only works for C# because the notebook extension is Rosyln specific. Thirdly this no longer works in notebooks at all because it uses BinaryFormatter which is disabled in net5.
Cloud function callbacks in dotnet pulumi
Pulumi is a multi-language framework for deploying cloud resources, like Terraform but with real code. When using Pulumi with javascript it has the ability to take an inline javascript closure and serialise that to be used by a cloud function (such as an Azure function app):
// Copyright 2016-2019, Pulumi Corporation. All rights reserved.
import * as azure from "@pulumi/azure";
const resourceGroup = new azure.core.ResourceGroup("example");
// Create an Azure function that prints a message and the request headers.
async function handler(context: azure.appservice.Context<azure.appservice.HttpResponse>, request: azure.appservice.HttpRequest) {
let body = "";
const headers = request.headers;
for (const h of Object.keys(request.headers)) {
body = body + `${h} = ${headers[h]}\n`;
}
return {
status: 200,
headers: {
"content-type": "text/plain",
},
body: `Greetings from Azure Functions!\n\n===\n\n${body}`,
};
}
const fn = new azure.appservice.HttpEventSubscription("fn", {
resourceGroup,
callback: handler,
});
export let endpoint = fn.url;See that callback property which is just set to point to the function above. This feature is currently only available with javascript.
Cluster compute from dotnet notebooks
A more general case of the spark dotnet problem, but it would good to write a computationally heavy function in a dotnet notebook (C# or F#) and then send that to be computed using cluster resources.
Inspiration
Two of the above problems have already been solved in python using cloudpickle.
pyspark the python library for spark, uses cloudpickle to implement udfs, and at work we use cloudpickle to distribute functions from python notebooks to cluster machines. I imagine Pulumi could use cloudpickle to build cloud functions from python programs as well.
So if we had cloudpickle for dotnet we could probably solve these problems with that. So that’s what Pikala is, it’s a dotnet library with a similar design to cloudpickle.
Pikala
Pikala is a binary serialization library for dotnet. It makes an effort to try and serialize most objects, currently only MarshalByRef objects and pointers have explicit failures.
The major difference between Pikala and other serializers is it will also serialize type definitions and associated method code. These are then deserialized into dynamic modules when read. This allows you to pass a delegate pointing to a functioned defined in an interactive notebook to Pikala, send the serialized bytes to a remote cluster machine and have it rebuild that notebook function to execute it.
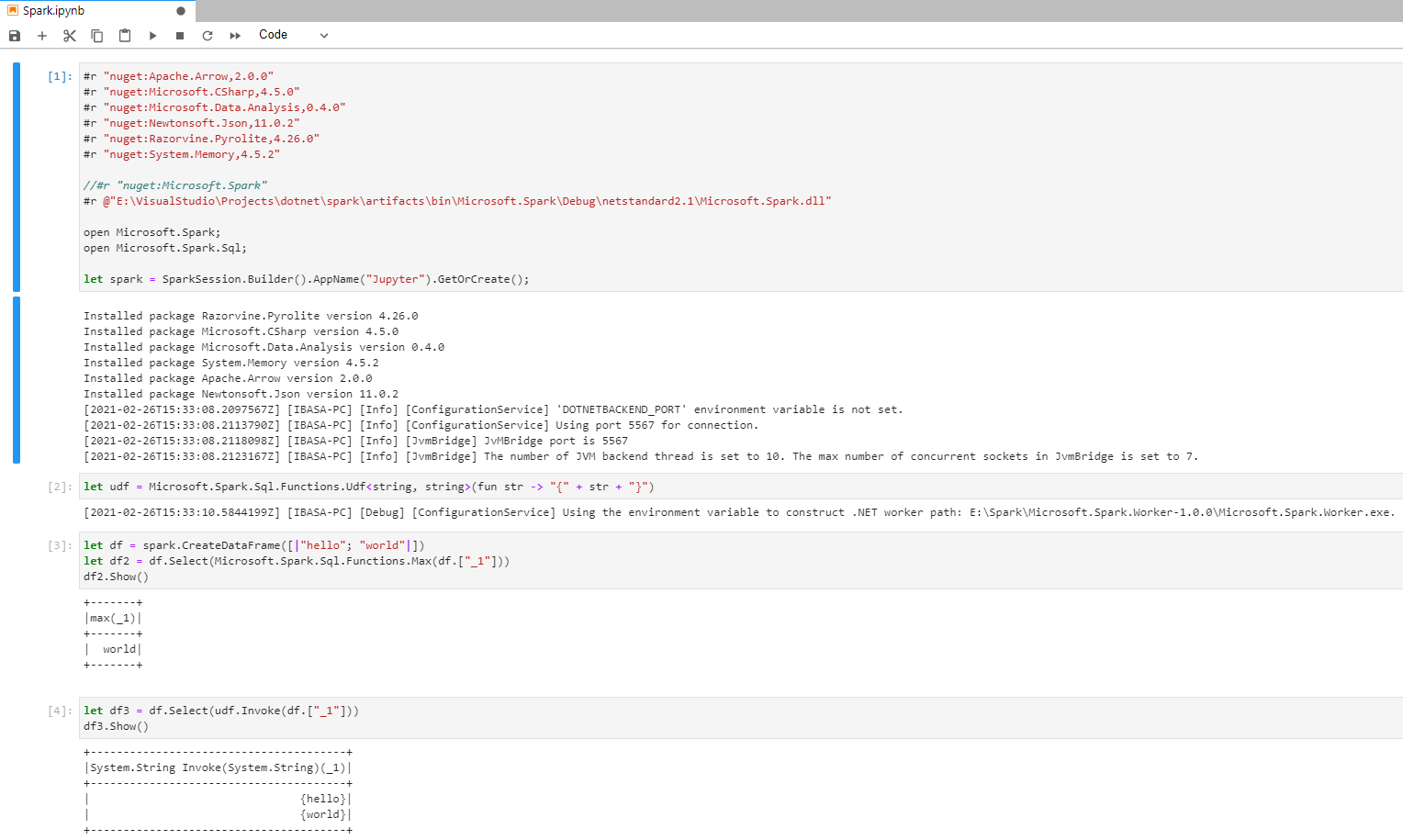
Spark dotnet with jupyter lab
The first Pikala field test was forking spark dotnet, replacing the BinaryFormatter with Pikala and trying to run a UDF defined in an F# notebook (F# just for extra proof in the pudding because currently dotnet spark doesn’t support this at all, there’s no F# notebook extension). You can see the fork here.
And the result:
Cloud function callbacks in dotnet pulumi
The second Pikala field test was deploying an Azure function app from pulumi without writing a separate dotnet project manually for the function.
I defined the following function in my Pulumi stack program:
public static class HelloDotnet
{
public static async Task<IActionResult> Run(HttpRequest req, ILogger log)
{
log.LogInformation("Pikala HTTP trigger function processed a request.");
string? name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
return name != null
? (ActionResult)new OkObjectResult($"Hello from Pikala, {name}")
: new BadRequestObjectResult("Please pass a name on the query string or in the request body");
}
}And then built an Azure function app from via a helper function to generate the executable blob:
var blob = WriteScript(ukStorageAccount, container, HelloDotnet.Run);
var codeBlobUrl = SharedAccessSignature.SignedBlobReadUrl(blob, ukStorageAccount);
var app = new FunctionApp("app", new FunctionAppArgs
{
ResourceGroupName = ukResourceGroup.Name,
AppServicePlanId = appServicePlan.Id,
AppSettings =
{
{"runtime", "dotnet"},
{"FUNCTIONS_WORKER_RUNTIME", "dotnet"},
{"WEBSITE_RUN_FROM_PACKAGE", codeBlobUrl},
{"APPLICATIONINSIGHTS_CONNECTION_STRING", Output.Format($"InstrumentationKey={insights.InstrumentationKey}")}
},
StorageAccountName = ukStorageAccount.Name,
StorageAccountAccessKey = ukStorageAccount.PrimaryAccessKey,
Version = "~3",
OsType = "linux",
SiteConfig = new FunctionAppSiteConfigArgs
{
AlwaysOn = true,
LinuxFxVersion = "DOCKER|mcr.microsoft.com/azure-functions/dotnet:3.0"
}
});That WriteScript did the magic to write out a dotnet function project to tmp, build it and pack it into a Pulumi FileArchive to be uploaded as part of an Azure stored blob. Note that the only parameters we’re passing into it are the Pulumi storage objects for where to store the blob and then a Func<HttpRequest, ILogger, Task<IActionResult>> delegate that’s pointed to our HelloDotnet.Run function. That entire function is serialized by Pikala and the function project is then just this template code:
using System;
using System.IO;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
namespace FunctionApp1
{
public static class Function1
{
[FunctionName("Function1")]
public static Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
var stream = new MemoryStream(Convert.FromBase64String("BASE64 PIKALA BYTES HERE"));
var pickler = new Ibasa.Pikala.Pickler();
var function = (Func<HttpRequest, ILogger, Task<IActionResult>>)pickler.Deserialize(stream);
return function(req, log);
}
}
}Very prototype code, but good enough for proof of concept that the idea could work.
Cluster compute from dotnet notebooks
Given the above it’s pretty easy to see how to extend this to use with cluster compute. Pikala your function of interest and then construct a script with those encoded bytes and send that script to the cluster.
Final thoughts
So this seems quite useful. It’s got the power to solve some real problems I’ve been hitting, so maybe it will help others as well. All code is LGPL3 at https://github.com/Ibasa/Pikala and usable from NuGet at https://www.nuget.org/packages/Ibasa.Pikala.